Локальный ИИ: данные не покидают ваш контур
Разворачиваем LLM, RAG и ML-модели на вашем сервере — или привозим своё железо. Без облака, без оплаты за токены, без утечек. Сами работаем на этом: наши компании живут на нашем же локальном ИИ. Нужно решение под ключ — вы на месте; нужен open-source стек в руки вашей команде — это раздел «Агентные платформы».

Когда к нам приходят
«Безопасность не пустила ChatGPT в прод»
Пилот на облачном API показал пользу, но СБ и юристы запретили отправлять данные наружу: коммерческая тайна, персональные данные, NDA с заказчиками.
«Зарубежные API — это риск»
Оплата через посредников, VPN, который отваливается, блокировки аккаунтов. Для процесса, который должен работать каждый день, это не инфраструктура.
«Токены съедают бюджет»
При росте нагрузки счёт за облачный ИИ растёт линейно и бесконечно. Локальная модель — это CAPEX вместо вечного OPEX: заплатили за железо один раз.
«Нужен ИИ по нашим документам»
Регламенты, договоры, техдокументация. Отдавать корпоративную базу знаний в чужое облако — не вариант.
«Облако могут просто выключить»
Провайдер меняет условия, блокирует регион, повышает цены. Локальную модель не отключит никто, кроме вас.
«Сервер купили — ИИ не появился»
Железо под локальные модели взяли, а дальше упёрлось: какую модель ставить, как подключить документы, кто будет поддерживать. Оборудование простаивает.
Что мы делаем
Полный спектр услуг для решения ваших задач
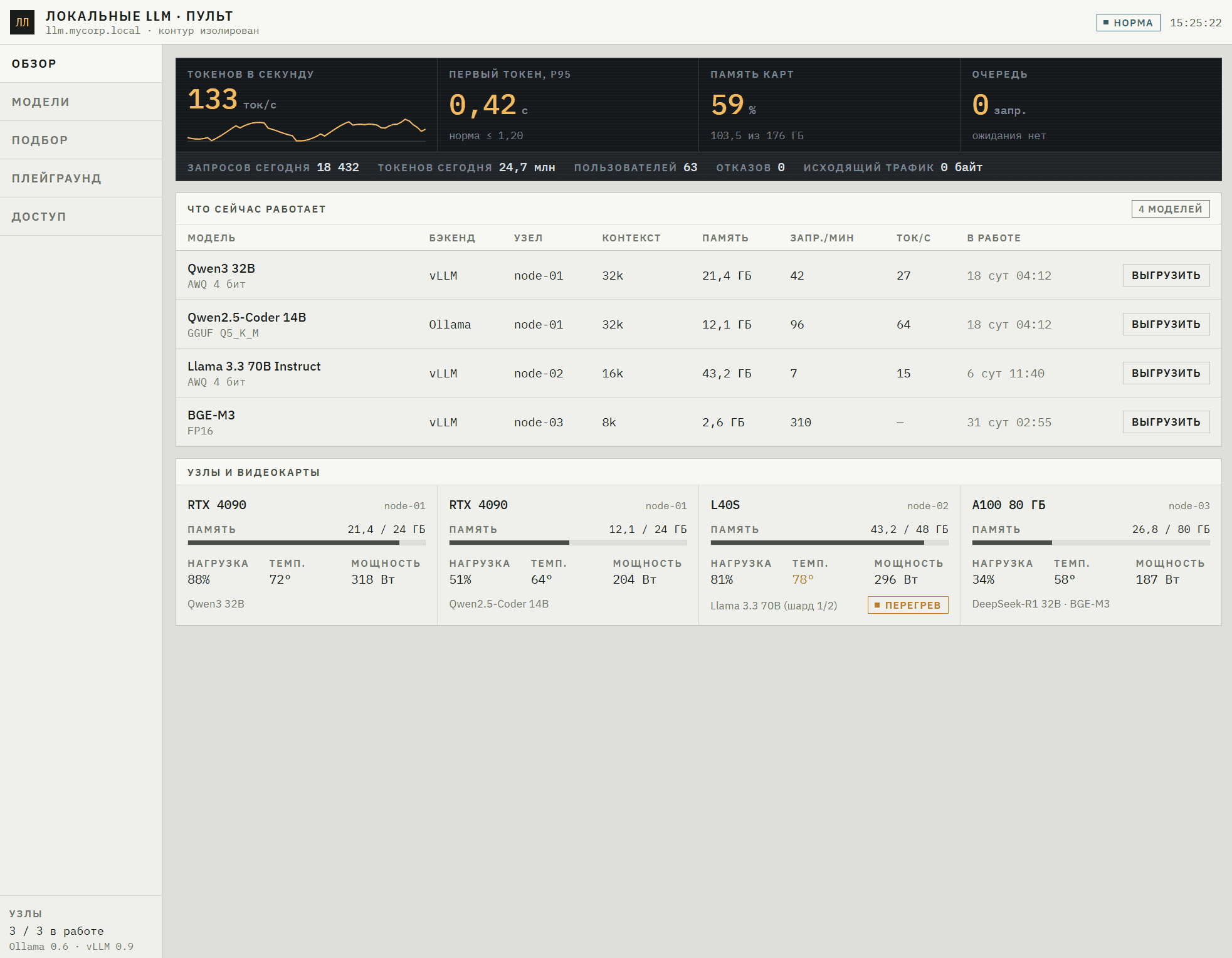
Локальные LLM под ключ
Разворачиваем открытые модели (Qwen, Llama, DeepSeek и другие) через Ollama или vLLM — на вашем сервере или поставляем вместе с железом. Подбираем модель под задачу и бюджет GPU: не «самую большую», а ту, что решает вашу задачу за разумные деньги.
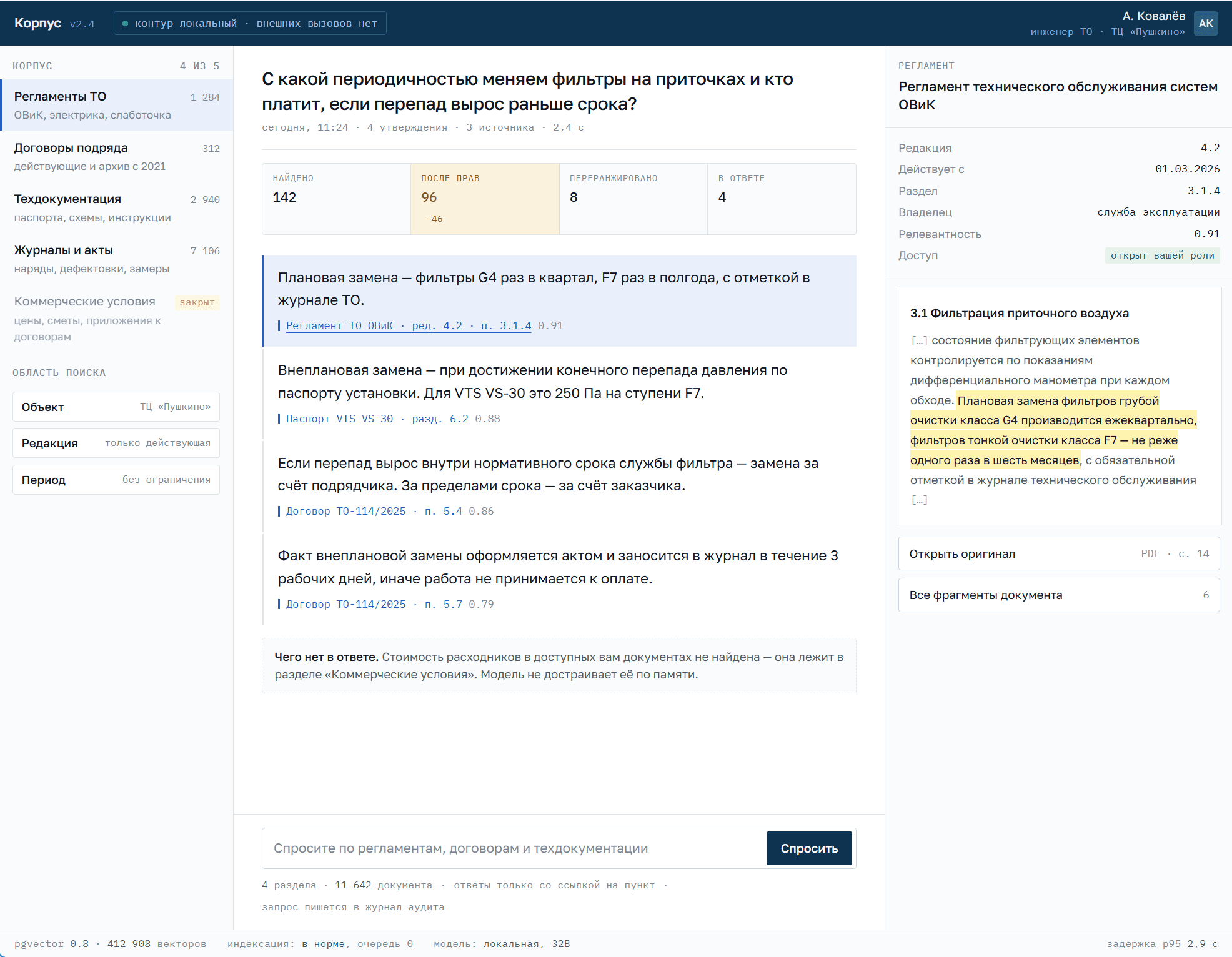
RAG: ИИ отвечает по вашим документам
Векторная база и пайплайн поиска — целиком в вашем контуре. Нейросеть отвечает по регламентам, договорам и техдокументации со ссылками на источник. Права доступа: кто не видит документ — не получит и ответ по нему.
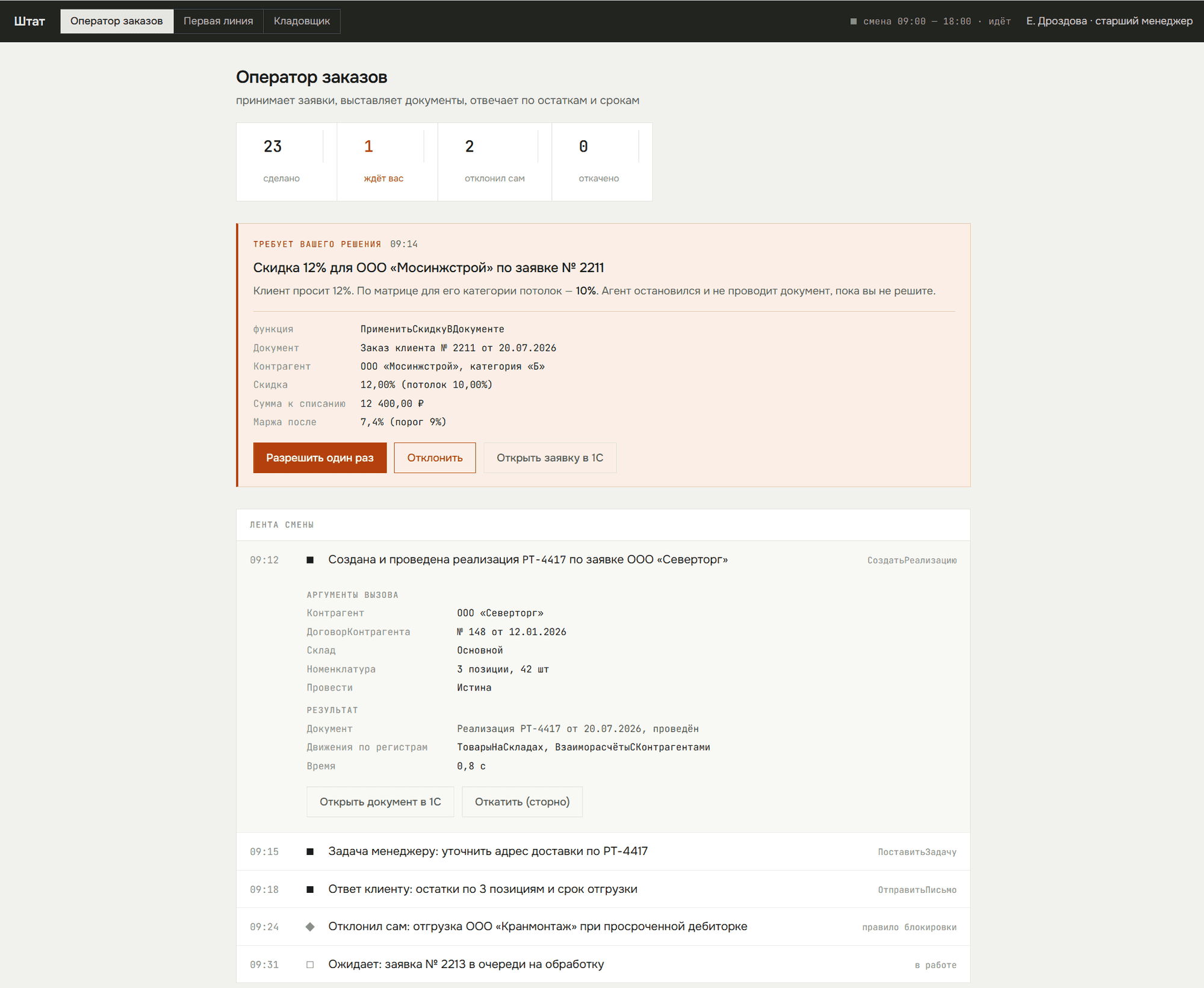
Цифровые сотрудники с function-calling
Агент не болтает, а делает: создаёт документы в 1С, ставит задачи, отвечает клиентам по данным из ваших систем. Интеграция вглубь — доработка конфигураций 1С своими руками, а не «через Zapier».
Голосовые агенты
Телефонная автоматизация на Asterisk: агент понимает речь, ходит в ваши данные и выполняет действия. Речевые движки подбираем под проект — от российских облачных сервисов до размещения в вашем контуре. Собственная платформа AIRA — в проде.
Edge ML: ИИ на устройстве
ONNX-модели прямо на контроллере, панели или промышленном ПК (C++/Python/Java). Без облака и даже без сервера — для задач, где важна автономность.
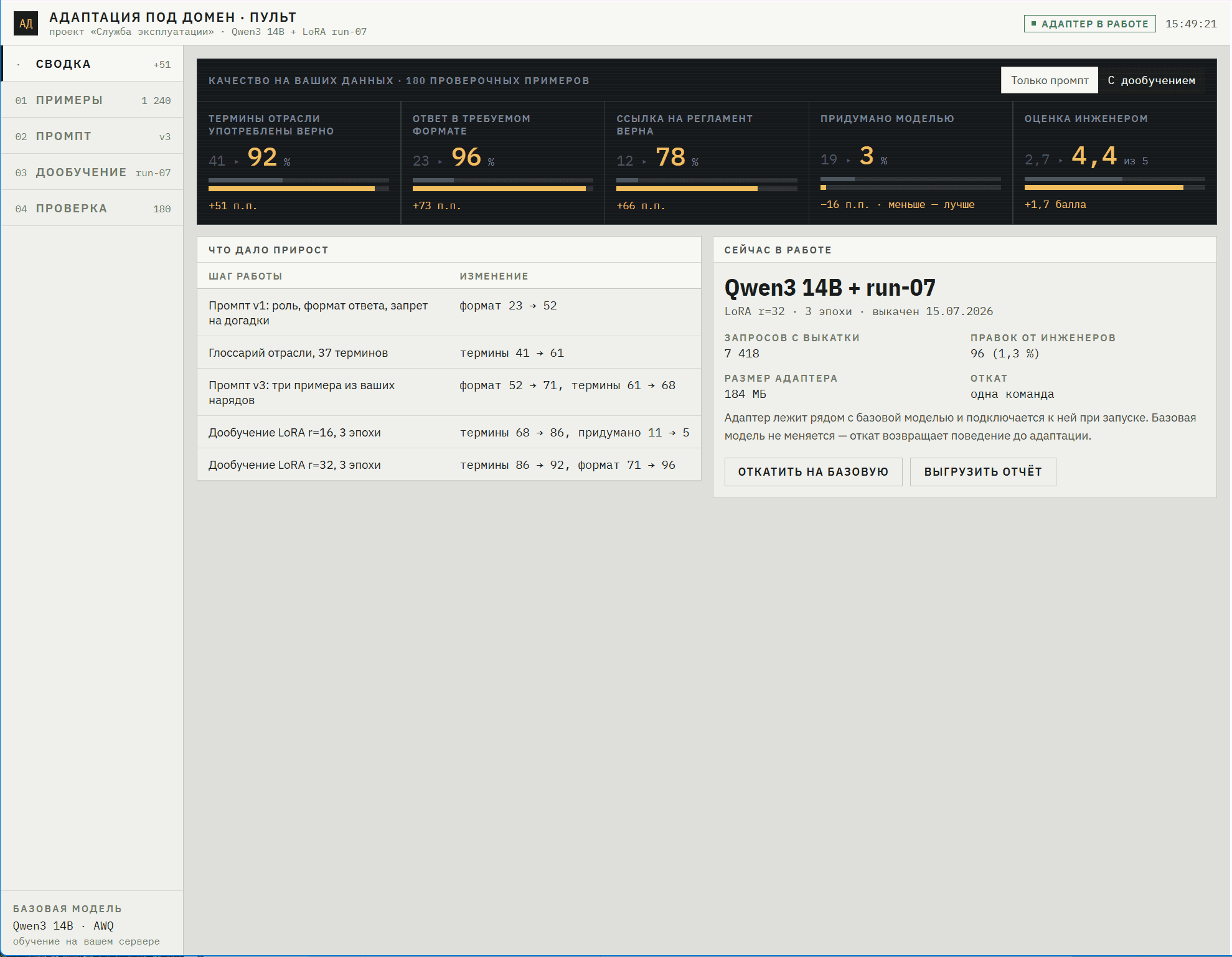
Адаптация моделей под ваш домен
Настройка промптов, дообучение на ваших примерах, оценка качества на ваших данных до и после — чтобы модель говорила на языке вашей отрасли.
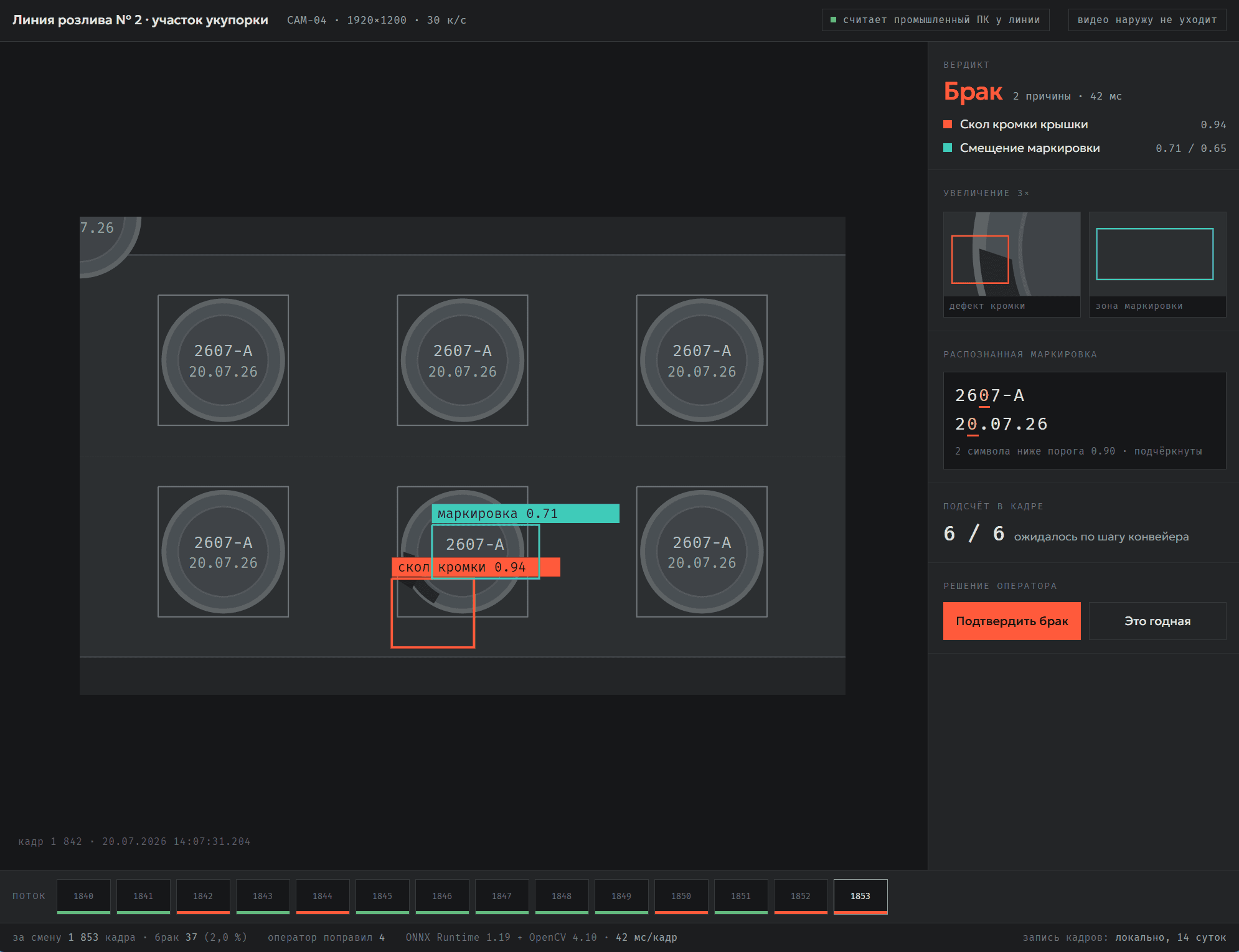
Компьютерное зрение и детекция
Модели детекции и распознавания (OpenCV, ONNX) на ваших изображениях и видеопотоке: контроль качества, распознавание маркировки, подсчёт объектов. Работают на вашем сервере или прямо на устройстве — видео не уходит в облако.
Предиктив по данным мониторинга
Модели на телеметрии оборудования: отклонения параметров, деградация узлов, ранние признаки отказа. Опираемся на собственный продукт мониторинга и опыт инженерных объектов.
Сначала пилот на ваших данных
Модель, которая хорошо отвечает на демонстрационных примерах, может не справиться с вашими документами. Проверяем до внедрения, а не после.
Данные
Смотрим, что за документы и в каком виде: форматы, объём, права доступа, что считается верным ответом.
Модель
Подбираем под задачу и бюджет GPU — не самую большую, а ту, что решает вашу задачу за разумные деньги.
Пилот
Разворачиваем в вашем контуре, на ваших данных, с критериями успеха, о которых договорились заранее.
Как мы работаем
Прозрачный процесс от первого звонка до запуска
Аудит задачи
Что автоматизируем, какие данные, какие системы задействованы.
БесплатноПодбор стека
Модель, железо (ваше или наше), способ интеграции. Фиксируем критерии успеха пилота.
Засчитывается в проектПилот на ваших данных
Рабочий прототип в вашем контуре, замер качества на реальных кейсах.
В вашем контуреВнедрение
Интеграция с 1С и другими системами, права доступа, обучение команды.
ИнтеграцияСопровождение
Обновление моделей, мониторинг качества, развитие сценариев.
По договоруАудит задачи
Что автоматизируем, какие данные, какие системы задействованы.
БесплатноПодбор стека
Модель, железо (ваше или наше), способ интеграции. Фиксируем критерии успеха пилота.
Засчитывается в проектПилот на ваших данных
Рабочий прототип в вашем контуре, замер качества на реальных кейсах.
В вашем контуреВнедрение
Интеграция с 1С и другими системами, права доступа, обучение команды.
ИнтеграцияСопровождение
Обновление моделей, мониторинг качества, развитие сценариев.
По договоруЧто вы получаете
- Система работает на вашем железе
Не доступ к нашему сервису, а развёрнутое у вас решение.
- Модель, база и данные — ваши
Остаются в периметре, включая этап пилота.
- Промпты и пайплайны передаются
Вместе с описанием, как это устроено.
- Команда обучена
Меняете сценарии, добавляете документы, обновляете модель без нас.
Локальный ИИ имеет смысл, только если он остаётся вашим. Мы не держим ключ от вашей системы — сопровождение это выбор, а не необходимость.
Кейсы
Реальные проекты и результаты наших клиентов

AI-аудит BMS офисного здания на Цветном бульваре
Оценить состояние инженерных систем действующего объекта на Niagara 4.8 за одну сессию, без остановки оборудования.
Автоматический съём полной конфигурации и исторических трендов, анализ компонентов и точек без ручной работы в Workbench.
57 фанкойлов и 344 компонента разобраны, выгружено 32 тренда, выявлено 6 критических проблем — включая обратный поток теплоносителя.
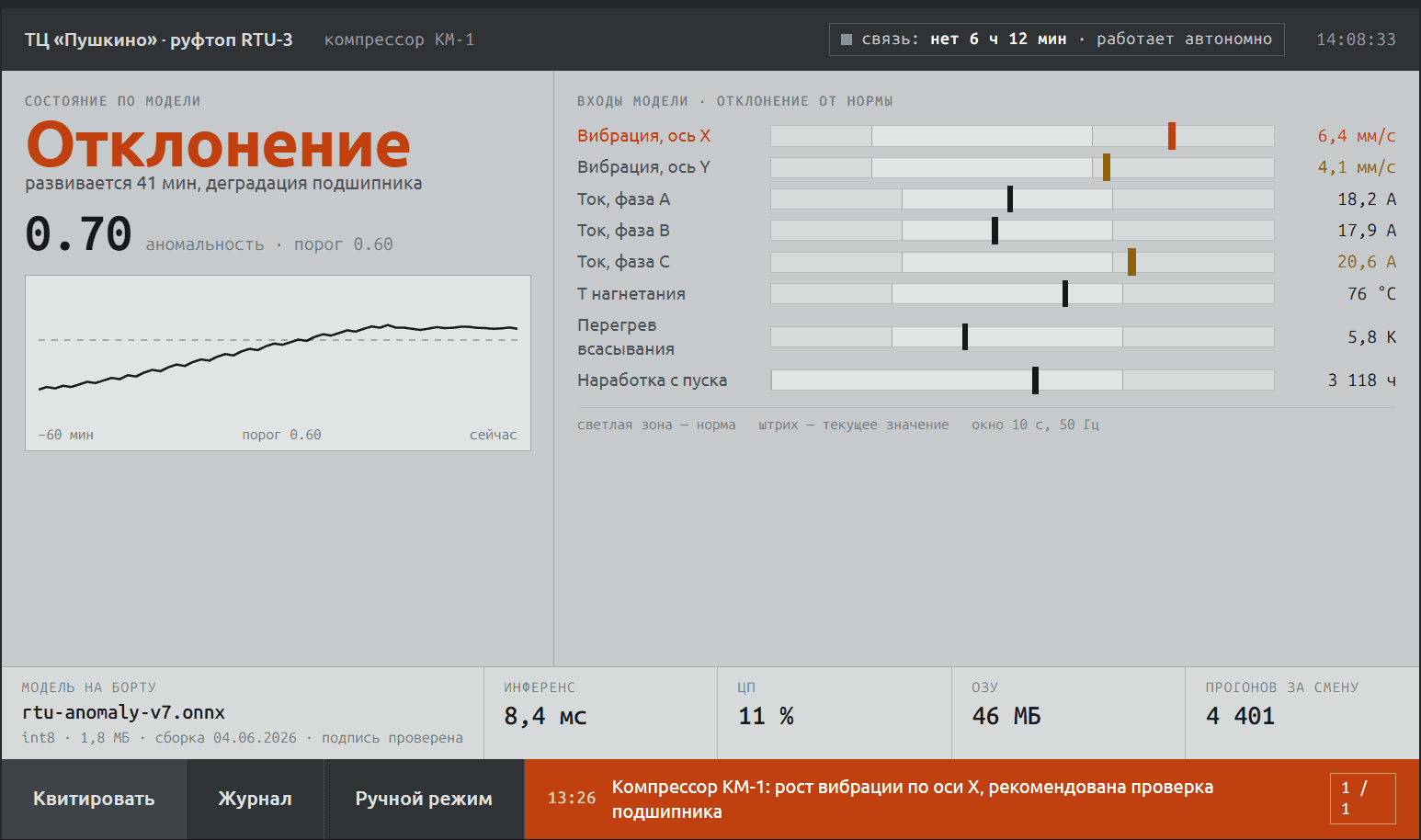
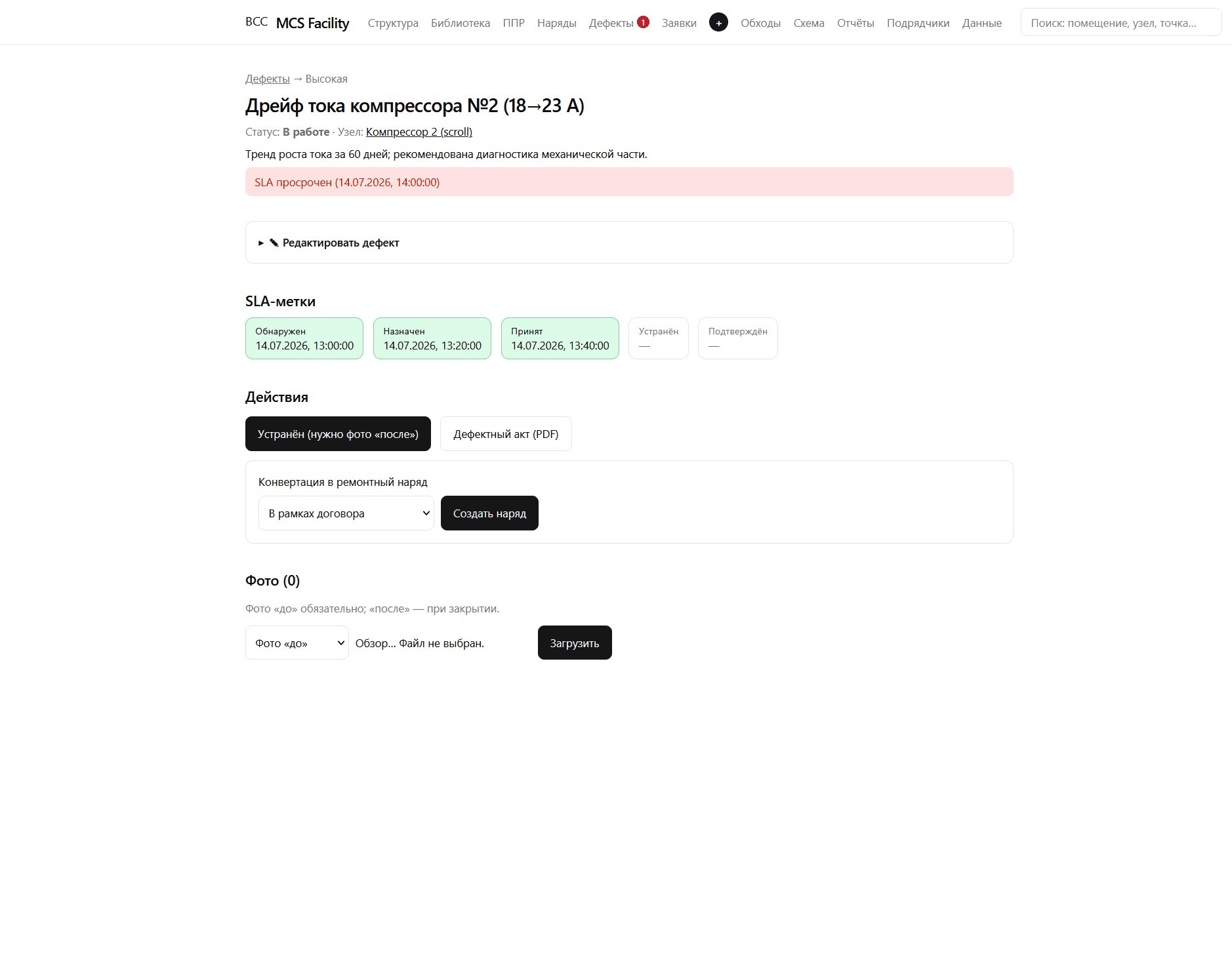
Предиктив: ранний признак отказа компрессора
Заметить деградацию оборудования до отказа, а не по факту аварии.
Расчётная модель состояния по весам и коэффициентам узлов; тренды параметров за 60 дней; отклонение автоматически становится дефектом с рекомендацией и SLA-метками.
Рост тока компрессора 18→23 А зафиксирован трендом, дефект заведён с рекомендацией диагностики механической части и переведён в ремонтный наряд.
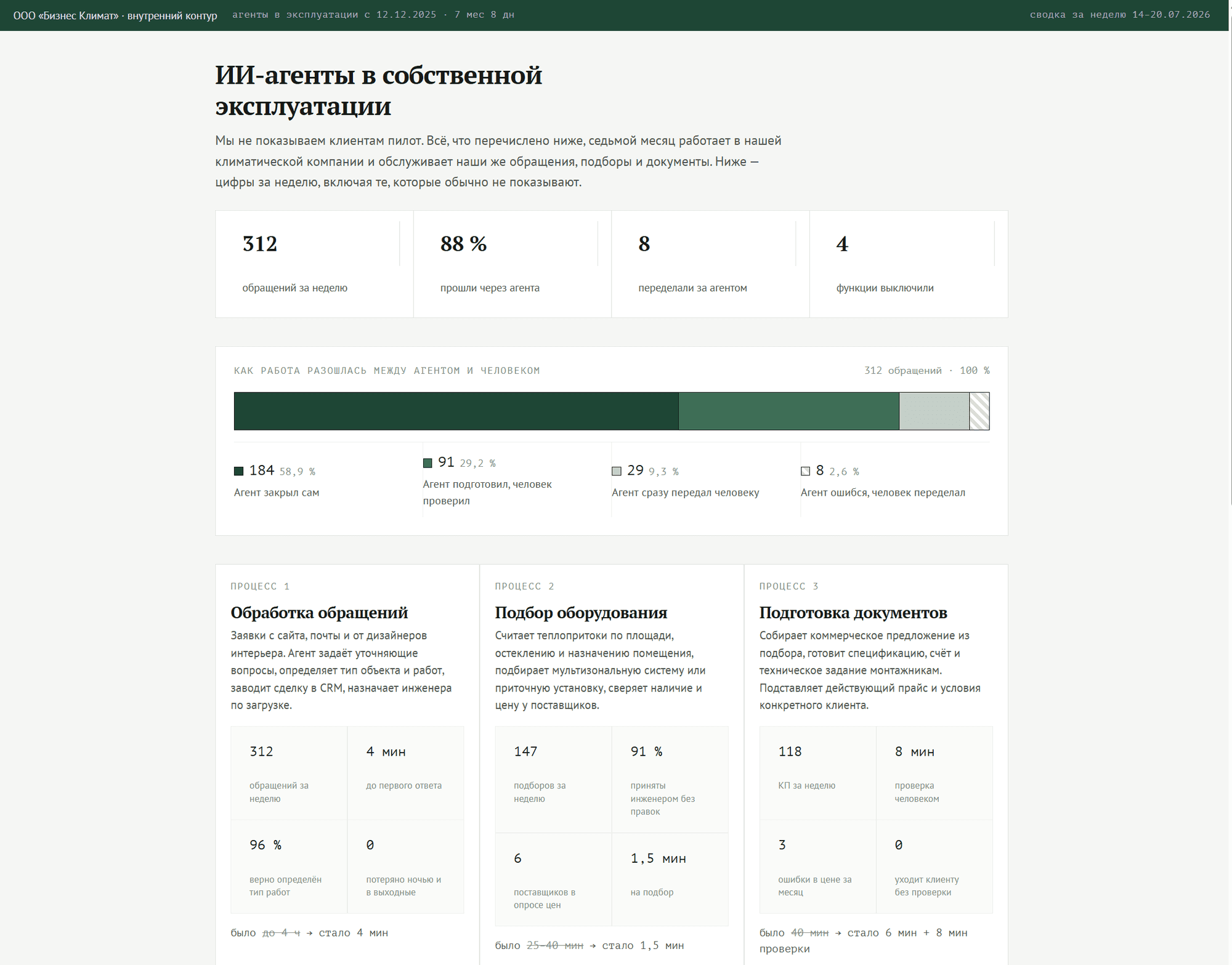
AIRA — голосовой агент в собственной климатической компании
Разгрузить сотрудников, которые каждый день отвечают на одни и те же вопросы, уточняют данные клиента и вручную заводят заявки.
Голосовая платформа на Asterisk с распознаванием речи и вызовом инструментов: агент понимает суть обращения, уточняет оборудование, адрес и срочность, создаёт заявку и передаёт сотруднику в структурированном виде. Платформа развёрнута в собственном контуре, речевые движки переключаются под требования проекта.
Агент работает в четырёх каналах — голос, текст, Telegram и MAX; доля автоматизированных диалогов измеряется против целевого порога.
Технологический стек
Инструменты и технологии, которые мы используем
Локальные модели
Инференс и раздача
RAG и агенты
Компьютерное зрение
MLOps и наблюдаемость
Инфраструктура
Частые вопросы
С чего начнём
Бесплатный аудит: разберём вашу задачу, данные и контур, покажем на живом стенде, как работает локальная модель. После аудита — фиксированное предложение на пилот в вашем контуре с критериями успеха, о которых договоримся заранее. Работаем по договору с ООО, с закрывающими документами.
Направления ИИ
Готовы внедрить AI?
Проведём бесплатный discovery-воркшоп и покажем, где AI принесёт максимальный ROI. PoC на нашем сервере.
Другие направления